2024年5月28日,多家SEO媒体网站发布了谷歌搜索涉及2500多页内部文件泄露的事件。一直以来谷歌SEO社区和从业人员一直在研究Google搜索引擎的排名算法,借着此次事件,我们有机会对谷歌搜索排名算法的内部工作原理一探究竟。
最早在3月13日,名为yoshi-code-bot的自动化机器人在Github上发布了2500多份疑似来自Google内部内容API仓库的文档。泄露路径是,这些内部文档的已弃用版本意外地公开发布到Google客户端库的代码存储库中,然后该代码的文档由外部自动文档服务捕获,被发布到Github。根据更改历史记录,Google代码存储库错误已于5月7日修复,但发布在Github上的自动化文档仍然有效。
5月初,SparkToro的联合创始人兰德·菲什金(Rand Fishkin,也是MOZ的创始人和前CEO)收到匿名人士的邮件,该人士称 Google 搜索部门内部的 API 文档大量泄露,可以公开访问。经过一些前谷歌员工核查,这些泄露的文件大概率是真实的。
截至5月27号,泄密文档经由SparkToro联合创始人Rand Fishkin和iPullRank首席执行官Michael King审查分析,并给出了初步分析结论。感谢Rand Fishkin和Michael King的解读,我们现在可以一睹这些内部文档的概况。
一、泄露API文档内容概览
文档的真实性:经过几名前谷歌员工以及SEO专家Michael King的审查分析,这些文档几乎可以确信是Google 搜索部门内部的一组合法文件,并且包含大量先前未经证实的有关 Google 内部运作的信息。不过不能确信这些泄露文件是该文档的最新版本。在 API 文档中找到引用的最新日期是2023年8月,可以证明文档在去年8月前是有效的。另外需要考虑的是,谷歌搜索每年都在发生巨大变化,因此建议读者不要把此次泄露中的某个特定API功能来作为谷歌在排名算法中使用某某因素的证据。
文档内容:包含2,596个模块和14,014个属性。泄露的文档概述了API的每个模块,并将它们分解为摘要、类型、函数和属性。我们主要关注的大部分内容是各种协议缓冲区的属性定义,这些协议缓冲区可以跨排名系统访问以生成 SERP(搜索引擎结果页面)。因此研究这些属性,就可以揭开一部分Google搜索排名因素的神秘面纱。
二、泄露API文档揭露了谷歌的一些“谎言”
谷歌官方发言人或者谷歌相关专家曾经说过的话,然而这些发言可能被证实是“谎言”:
- 谷歌不使用域名权重进行排名;
- 不使用点击次数来排名;
- 谷歌搜索排名没有沙盒;
- 谷歌不会使用Chrome浏览器数据进行自然搜索排名;
尽管我们还是相信发布这些信息的谷歌官方人员都会尽最大努力在允许的范围内为SEO社区提供支持和价值,然而泄露的文档似乎表明事实正是这些“谎言”的反面。虽然我们不能完全确信这些文档的真实性,我们所能做的应该是继续进行SEO排名实验,看看什么才是真实有效的。
更新信息:截至5月29日,谷歌已对文档泄密事件做出回应:基于数据泄露发布的许多假设都是断章取义、不完整的,并补充说搜索排名信号在不断变化。参阅:谷歌回应文档泄密事件:断章取义
三、谷歌搜索排名系统的架构
从概念上讲,我们可能会将“Google 算法”视为一个东西,一个包含一系列加权排名因素的巨型方程。但实际上,它是一系列的微服务,其中许多功能经过预处理并在运行时可用以组成搜索引擎排名结果。根据文档中引用的不同系统,可能有一百多个不同的排名系统。假设这些每个单独的系统都代表一个“排名信号”,那也许这就是SEO社区经常讨论的Google 200个排名因素的由来。
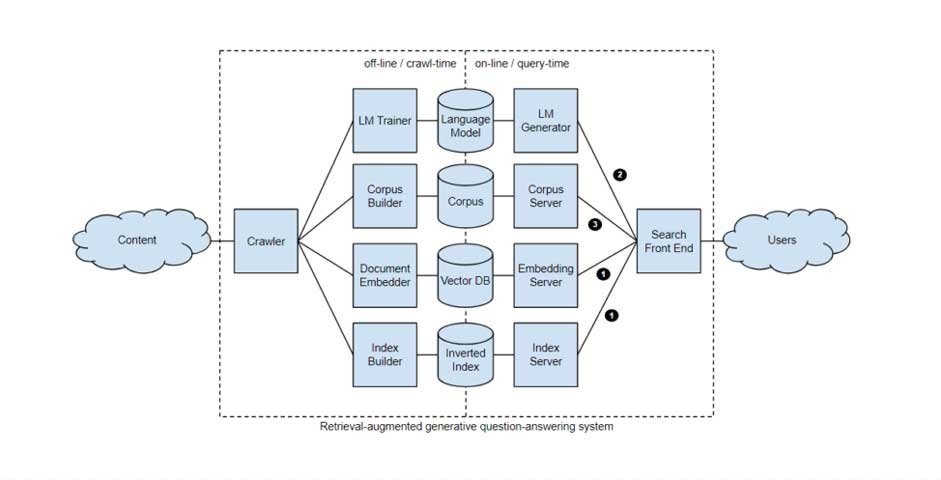
爬取
Trawler – 网络爬行系统,具有爬行队列、维护爬取率并了解页面更改的频率。
索引
Alexandria – 核心索引系统。
SegIndexer – 将分层文档放入索引内的分层的系统。
TeraGoogle – 长期驻留在磁盘上的文档的辅助索引系统。
渲染
HtmlrenderWebkitHeadless – JavaScript 页面的渲染系统。
加工
LinkExtractor – 从页面中提取链接。
WebMirror – 用于管理规范化和复制的系统。
排名
Mustang – 主要评分、排名和服务系统。
Ascorer – 在任何重新排名调整之前对页面进行排名的主要排名算法。
NavBoost – 基于用户行为点击日志的重新排名系统。
FreshnessTwiddler – 基于新鲜度的文档重新排名系统。
WebChooserScorer – 定义片段评分中使用的功能名称。
服务
Google Web Server –GWS 是 Google 前端与之交互的服务器。它接收数据的有效负载以显示给用户。
SuperRoot – 这是 Google 搜索的大脑,它将消息发送到 Google 的服务器并管理后处理系统,以重新排名和呈现结果。
SnippetBrain – 生成结果片段的系统。
Glue – 利用用户行为将通用结果整合在一起的系统。
Cookbook – 生成信号的系统。
什么是Twiddlers框架?
Twiddlers 是在主要 Ascorer 搜索算法之后运行的重新排序函数。它们的操作方式类似于 WordPress 中的过滤器和操作的工作方式,其中显示的内容在呈现给用户之前进行调整。 Twiddlers 可以调整文档的信息检索分数或更改文档的排名。我们所知道的许多现场实验和命名系统都是通过这种方式实现的。它们在各种 Google 系统中都非常重要。
Twiddlers 可以提供类别限制,这意味着可以通过具体限制结果类型来促进多样性。
据推测,任何带有 Boost 后缀的函数都使用 Twiddler 框架运行。以下是文档中确定的一些增强功能:
- NavBoost 导航助推器
- QualityBoost 质量提升
- RealTimeBoost 实时增强
- WebImageBoost 网页图像增强

四、可能影响SEO的关键启示
1. 熊猫算法的工作原理
熊猫算法(Panda Algorithm)推出的时候,引起了很多混乱。人们对它有很多疑问。它是机器学习吗?它使用用户信号吗?为什么我们需要更新或刷新才能恢复?影响是全站的吗?为什么某个子目录的流量没了?
现在对比Panda的专利和这些API文档,发现它远比想象的简单。Panda有一系列专注于网站质量的专利,是基于与用户行为和外部链接相关的分布式信号构建评分修改器,可以应用于域级别、子域或子目录级别。
Panda的参考查询是来自 NavBoost 的查询。Panda的刷新只是对查询滚动窗口的更新,类似于 Core Web Vitals 计算的功能。这也可能意味着 Panda 没有实时处理链接图的更新。Panda的另一项专利“站点质量评分”,也考虑了参考查询与用户选择或点击之间的比率的分数。
2. 作者(Authors)标记是一个显性特征
网上关于E-E-A-T 的文章很多,不过我们对于专业知识和权威这一排名因素还是十分模糊。似乎作者身份(Authorship)排名因素上不是一个足够可行的信号。
尽管如此,谷歌确实明确地将与文档相关的作者(Authors)存储为文本,同时还希望确定页面上的实体是否也是该页面的作者。
3. 在搜索算法中降级的因素
- 锚点不匹配:当链接与其链接到的目标站点不匹配时,该链接将在计算中降级。正如我之前所说,谷歌正在寻找链接两侧的相关性。
- SERP降级:根据从 SERP 观察到的因素指示降级的信号,表明用户对页面的潜在不满意(可能通过点击来衡量)。
- 导航降级:据推测,这是应用于表现出不良导航问题或用户体验问题的页面的降级。
- 精确匹配域降级:在2012年就宣布的一个消息,得到了证实,域名精确匹配在排名因素中降级。
- 产品评论降级:没有这方面的具体信息,但它被列为降级,可能与 2023 年最近的产品评论更新有关。
- 位置降级:有迹象表明“全局”页面和“超级全局”页面可以降级。这表明谷歌试图将页面与位置相关联并相应地对它们进行排名。
- 色情降级:这一点非常明显。
4. 链接仍然非常重要
(1)索引层影响链接价值
Google 的索引分为几层,其中最重要、定期更新和访问的内容存储在闪存中。不太重要的内容存储在固态硬盘上,不定期更新的内容存储在标准硬盘上。这意味着索引层级别越高,链接的价值就越高。“新鲜”的页面比旧的页面质量更高。简而言之,来自新鲜的页面或位于顶层的其他页面的链接的价值越高。
(2)垃圾链接的速度信号
Google能够有效地测量垃圾链接的速度信号,这可以很容易地用于识别网站何时发送垃圾邮件并消除负面 SEO影响。
(3)Google 在分析链接时仅使用给定URL的最后20个更改记录
谷歌的文件系统被猜测能够像网站时光机(Wayback Machine)一样随着时间的推移存储页面的版本。现在,文档暗示谷歌保留了他们在页面上看到的所有更改。同时文档显示,谷歌通过检索DocInfo进行表面数据比较时,只考虑该页面的20个最新版本。从这里我们应该明白需要多少次更改页面并将其编入索引才能在 Google 中获得“干净的记录”。
(4)所有页面均考虑主页的PageRank
主页很可能被用作新页面的代理,直到这些新页面计算出自己的PageRank。
(5)主页信任
谷歌根据他们对主页的信任程度来决定如何评估链接。应该关注链接的质量和相关性,而不是数量。
(6)术语和链接的字体大小很重要
文档显示,谷歌正在跟踪页面中术语的平均加权字体大小,比如链接的锚文本。
(7)企鹅算法去掉了内部链接因素
企鹅算法(Penguin Algorithm)是谷歌为了提高搜索结果质量而推出的一项重要更新,意在打击不自然的反向链接,降权那些充斥着广告的网站。在许多锚点相关模块中,一些内部链接没有被计算“本地”概念之内。这意味着一些内部链接在链接算法中被忽略了。
(8)拒绝链接(Disavow Link)可能并不起作用
没有看到任何提及拒绝(Disavow)的内容。拒绝数据没有专门存储在这个API中。质量评估者数据可以在这里直接访问,这意味着拒绝数据与核心排名系统脱钩。
5. 文档截断问题
Google会计算token的数量以及正文中总单词数与唯一token数量的比率。文档指出,Mustang系统中的文档可以考虑使用最大数量的标记,因此最重要的内容还是应该放在一篇文章中更前面的位置。
6. 短内容的原创性评分
短内容并不总是使用长度函数,谷歌会对短内容的原创性进行评分。当然,还是要避免关键词堆砌。
7. 页面标题仍然根据查询来衡量
文档表明有一个标题匹配评分。表明页面标题与查询的匹配程度仍然是Google积极重视的因素。标题放置目标关键字仍然是一个好的举措。
8. 没有字符计数指标
此文档集中没有任何指标可以计算页面标题或摘要的长度。似乎可以证明:冗长的页面标题对于推动点击量来说可能不是最佳选择,但对于推动排名来说却很好。
9. 日期非常重要
谷歌非常注重新鲜结果,这些文件说明了其将日期与页面关联起来的无数次尝试。文档出现了多个从页面采集日期的函数:
- bylineDate:页面上明确设置的日期
- syntacticDate:从 URL 或标题中提取的日期
- semanticDate:这是从页面内容派生的日期
最好的方法是指定一个日期,并在结构化数据、页面标题、XML站点地图中保持一致。在URL中放置于页面其他位置的日期冲突的日期可能会降低内容的表现。
10. 存储有关页面的域名注册信息
谷歌文档中提及了算法在存储最新的域名注册信息。这可能用于通知新内容的沙箱,也可能用于过期域名滥用垃圾邮件的问题。
11. 以视频为中心的网站受到不同的对待
如果网站上超过50%的页面包含视频,则该网站将被视为以视频为主,并将受到区别对待。
12. Your Money Your Life 这一排名因素是专门评分
文档表明,Google 拥有可以为 YMYL 健康和 YMYL新闻生成分数的分类器。谷歌还对“边缘查询”或以前从未见过的查询进行预测,以确定它们是否是YMYL。
YMYL 以块级别为核心,这表明整个系统基于嵌入的。
13. 存在黄金标准
文档中只标注了golden标记,在描述中提到了 “人工标注文档 ”与 “自动标注注释”。没有说明这意味着什么,谷歌搜索算法中可能存在某种黄金标准,尽管我们不知道在意味着什么。只能等待后续的验证了。
14. 站点嵌入用于衡量页面的主题偏离程度
Google 专门对页面和网站进行矢量化,并将页面嵌入与网站嵌入进行比较,以了解页面的偏离主题程度。谷歌使用siteFocusScore函数捕获网站对单个主题的关注程度。站点半径根据为站点生成的向量捕获页面超出核心主题的距离。因此文章的主题聚焦程度是内容排名表现的一个重要因素。
15. 谷歌对小型网站可能区别对待
Google有一个特定的标记,表明该网站是“小型个人网站”。目前对此类网站没有定义,不过谷歌如果想要对小型个人网站进行单独的评分,是很容易添加一个Twiddler来提升或降低此类网站的排名的。
后续追踪
SEO专家Michael King在与Rand Fishkin沟通后,只用了一个周末的时间对这些文档做分析,因此还存在诸多疑问。他承诺会利用接下来几个月的时间进行更深入的分析,并在今年10月8日的西雅图SparkTogether 2024会上更详细地介绍此次文档泄露的故事。
Rand Fishkin也说,这些文档太大、太密集,以至于无法想象一个周末的浏览就能挖掘出一套全面的、抑或是接近的收获。因此,他预计未来几年将会从这个庞大的文件集中挖掘出有趣且适用于营销的见解。
此次文件泄露为SEO社区提供了前所未有的对Google搜索内部工作机制的洞察机会。我们将会继续关注这2500多页文档的后续分析见解。